Chi-Square Feature Selection.
Description.
This is a Chi-Square feature selection module based on the research done by Wang, D., Liang, Y., Xu, D., Feng, X., & Guan, R. [1] that processes scientific journal abstract data, written in NodeJs. This module will determine the most dependent set of words to a given set of journals. The more dependent a word is on a journal, the more representative that word is to the journal. This module uses a version of the Chi-Square equation from [1] to calculate the dependence of a word to a journal based on the following formula :

Where :
- A is the number of documents including word t, which belongs to journal c.
- B is the number of documents including word t, which does not belong to journal c.
- C is the number of documents in journal c, which does not include the word t.
- D is the number of documents in journals other than journal c, which does not include the word t.
Here is the link to access the Github repository.
Background.
This is a sub-project for my Bachelor’s thesis. My main thesis project was to build a Journal Recommender Application using a Softmax Regression model as the classifier. I already gathered textual data online using my Web Scraper, but the text is still in the form of complete paragraphs. So to turn the paragraphs into features that can be learned by the model, I created this sub-project.
Features.
- Aggregates 150 words with the highest Chi-Square value for each journal and remove any duplicate words.
- Groups 150 words with the highest Chi-Square value for each journal by their respective journals.
- Logs the A, B, C, D variables for each word to each journal as well as their Chi-Square values.
Input.
The input file can be found in the ./data/input/ directory, which stores a list of JSON objects with the following structure :
[
{
"JOURNAL_ID": 0,
"JOURNAL_TITLE": "Jurnal Hortikultura",
"ARTICLE_ID": 0,
"ARTICLE_TITLE": "SISTEM TANAM TUMPANG SARI CABAI MERAH DENGAN ... DAN BUNCIS TEGAK ",
"ARTICLE_ABSTRACT": "Pola tanam tumpang sari merupakan salah satu cara untuk meningkatkan efisiensi ... tumpang sari cabai dengan kentang dan bawang merah merupakan usahatani yang paling menguntungkan terutama apabila dibandingkan dengan monokultur.",
"TOKENS": [ "pola", "tanam", "tumpang", "sari", "rupa", "salah", "tingkat", "efisiensi", ... , "tumpang", "sari", "usahatani", "tumpang", "sari", "cabai", "kentang", "bawang", "merah", "rupa", "usahatani", "untung", "utama", "banding", "monokultur" ],
"TOKENS_DUPLICATE_REMOVED": [ "pola", "tanam", "tumpang", "sari", "rupa", "salah", ... , "tumbuh", "vegetatif", "beda", "nyata", "tara", "untung", "bersih", "usahatani", "utama", "banding" ]
},
... ,
{
"JOURNAL_ID": Number,
"JOURNAL_TITLE": String,
"ARTICLE_ID": Number,
"ARTICLE_TITLE": String,
"ARTICLE_ABSTRACT": String,
"TOKENS": Array,
"TOKENS_DUPLICATE_REMOVED": Array
}
]
Output.
This module produces three different files with differing outputs:
-
The file in the
./data/output/fv-tokens.jsondirectory is used to save the 150 aggregated words with the highest Chi-Square value for each journals and removes any duplicate words.[ "tanam", "balai", "varietas", "ulang", "sayur", ... , "kawat", "struktur", "superplasticizer", "wulung" ] -
The file in the
./data/output/fv-tokens-by-journal.jsondirectory is used to save the 150 words with the highest Chi-Square values, grouped by their respectives journal IDs.{ "0": [ "tanam", "balai", "varietas", "ulang", "sayur", ... , "hasil", "manggis", "patogen" ], ... , "n_journals" : [ String, String, String, ... , String, String ] } -
The file in the
./data/output/chi-square-feature-vectors.jsondirectory is used to log the A, B, C, D, journal ID, and Chi-Square values for each word.[ { "JOURNAL_ID": 0, "TOKEN": "tanam", "A_VALUE": 626, "B_VALUE": 501, "C_VALUE": 137, "D_VALUE": 6633, "CHI_SQUARE": 2185638.198645179 }, ... , { "JOURNAL_ID": Number, "TOKEN": String, "A_VALUE": Number, "B_VALUE": Number, "C_VALUE": Number, "D_VALUE": Number, "CHI_SQUARE": Number } ]
Tools.
How to Run in Local Environment.
$ node src/index.js
Demo.
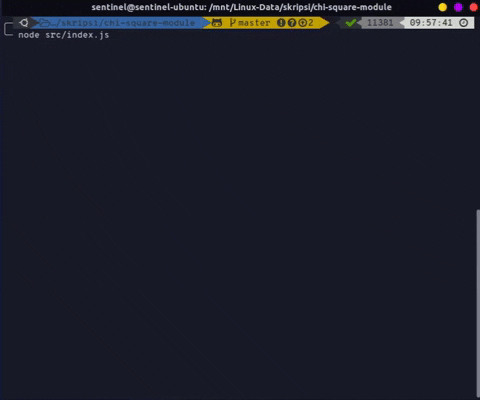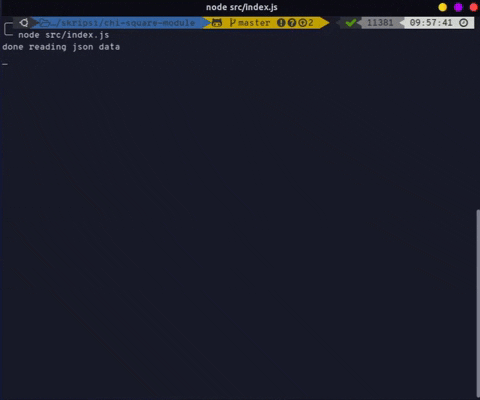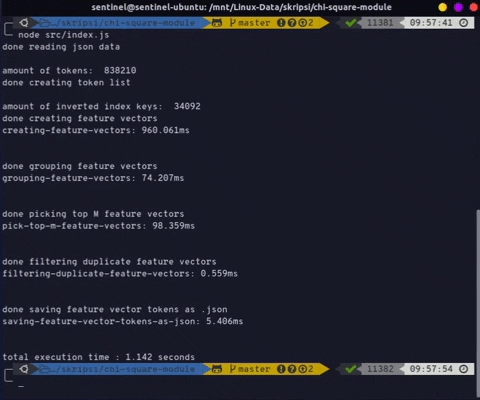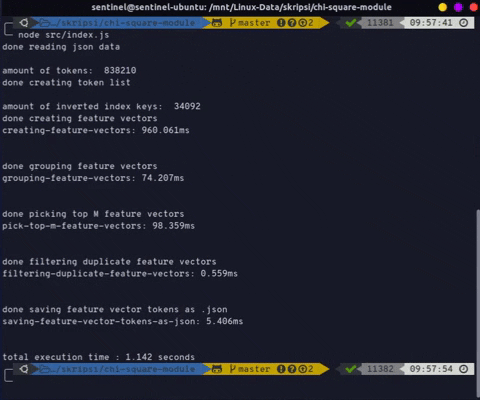
Reference.
- [1] Wang, D., Liang, Y., Xu, D., Feng, X., & Guan, R. (2018). A content-based recommender system for computer science publications.Knowledge-Based Systems, 157, 1-9.