Create APIs using Golang | Part 4 : Implementing Cache.

Introduction.
Databases serve as essential tools for storing data, but they can experience performance issues when dealing with massive transaction volumes. To address this challenge and introduce a faster data retrieval method, caching becomes a valuable solution.
What is Cache.
Cache, much like a database, serves as a data storage location. However, while databases store data on disk or drives, caches store data in memory. The organization of data in a cache is much simpler, making data retrieval significantly faster.
Nonetheless, storing data in memory has its drawbacks. Firstly, memory is volatile, meaning it retains data only while powered on; data is lost during power outages.
Secondly, caches have a limited data structure compared to persistent databases like relational, document-based, or graph databases. Caches primarily rely on key-value pairs, resembling a map data structure.
Implementing Cache.
For our cache engine, we’ll use Redis, along with the go-redis Golang client. Redis solves the persistence issue by saving data snapshots and writing them to disk, even when the server is off.
❗ Disclaimer ❗
The entire cache implementation is not included in this article because it would be too long. So if you’re following along with this article and run into missing codes, you can check out the Github repo.
package model
import "context"
type CacheRepository interface {
Get(ctx context.Context, key string) (reply string, err error)
Set(ctx context.Context, key, val string) (err error)
Delete(ctx context.Context, keys ...string) (err error)
}
Our cache implementation will be wrapped inside an interface, allowing easy switching of Golang Redis clients by changing its implementation.
package repository
import (
"context"
"github.com/redis/go-redis/v9"
"github.com/ssentinull/create-apis-using-golang/internal/model"
)
type cacheRepo struct {
redisClient *redis.Client
}
func NewCacheRepository(client *redis.Client) model.CacheRepository {
return &cacheRepo{redisClient: client}
}
func (c *cacheRepo) Get(ctx context.Context, key string) (string, error) {
val, err := c.redisClient.Get(ctx, key).Result()
if err != nil && err != redis.Nil {
return "", err
}
return val, nil
}
func (c *cacheRepo) Set(ctx context.Context, key, val string) error {
return c.redisClient.Set(ctx, key, val, 0).Err()
}
func (c *cacheRepo) Delete(ctx context.Context, keys ...string) error {
return c.redisClient.Del(ctx, keys...).Err()
}
go-redis implementation is pretty straightforward, all we need to do is provide a string key and a string value. The Set() and Delete() functions only return an error while the Get() function returns a string and an error.
package repository
import (
"context"
"encoding/json"
"fmt"
"github.com/sirupsen/logrus"
"github.com/ssentinull/create-apis-using-golang/internal/model"
"github.com/ssentinull/create-apis-using-golang/internal/utils"
"gorm.io/gorm"
)
type bookRepo struct {
db *gorm.DB
cacheRepo model.CacheRepository
}
func NewBookRepository(db *gorm.DB, cacheRepo model.CacheRepository)
model.BookRepository {
return &bookRepo{
db: db,
cacheRepo: cacheRepo,
}
}
func (br *bookRepo) Create(ctx context.Context, book *model.Book) error {
...
if err := br.cacheRepo.Delete(ctx, br.findAllCacheKey()); err != nil {
logger.Error(err)
return err
}
return nil
}
func (br *bookRepo) DeleteByID(ctx context.Context, ID int64) error {
...
cacheKeys := []string{
br.findByIDCacheKey(ID),
br.findAllCacheKey(),
}
if err := br.cacheRepo.Delete(ctx, cacheKeys...); err != nil {
logger.Error(err)
return err
}
return nil
}
func (br *bookRepo) FindByID(ctx context.Context, ID int64)
(*model.Book, error) {
cacheKey := br.findByIDCacheKey(ID)
reply, err := br.cacheRepo.Get(ctx, cacheKey)
if err != nil {
logger.Error(err)
return nil, err
}
if reply != "" {
book := &model.Book{}
if err := json.Unmarshal([]byte(reply), &book); err != nil {
logger.Error(err)
return nil, err
}
return book, nil
}
...
bytes, err := json.Marshal(book)
if err != nil {
logger.Error(err)
return book, nil
}
if err := br.cacheRepo.Set(ctx, cacheKey, string(bytes)); err != nil {
logger.Error(err)
}
return book, nil
}
func (br *bookRepo) FindAll(ctx context.Context) ([]*model.Book, error) {
cacheKey := br.findAllCacheKey()
reply, err := br.cacheRepo.Get(ctx, cacheKey)
if err != nil {
logger.Error(err)
return nil, err
}
if reply != "" {
books := []*model.Book{}
if err := json.Unmarshal([]byte(reply), &books); err != nil {
logger.Error(err)
return nil, err
}
return books, nil
}
...
bytes, err := json.Marshal(books)
if err != nil {
logger.Error(err)
return books, nil
}
if err := br.cacheRepo.Set(ctx, cacheKey, string(bytes)); err != nil {
logger.Error(err)
}
return books, nil
}
func (br *bookRepo) Update(ctx context.Context, book *model.Book)
(*model.Book, error) {
...
cacheKeys := []string{
br.findByIDCacheKey(book.ID),
br.findAllCacheKey(),
}
if err := br.cacheRepo.Delete(ctx, cacheKeys...); err != nil {
logger.Error(err)
return nil, err
}
return br.FindByID(ctx, book.ID)
}
func (br *bookRepo) findByIDCacheKey(ID int64) string {
return fmt.Sprintf("book:%d", ID)
}
func (br *bookRepo) findAllCacheKey() string {
return "book:all"
}
When fetching data, we first call our cache before querying the database. If there’s a cache hit, we immediately return the value. If not, we retrieve the data from the database and store it in the cache afterward.
Remember to invalidate the cache whenever data is inserted, updated, or deleted from the database to avoid stale data.
Creating a Database Seeder.
To make the data retrieval process more demanding for performance testing, we need to fetch a significant amount of data, possibly hundreds of entries. Instead of manually creating this data through our API or database client, we can use a database seeder to automate the process and generate rows of fake data.
We’ll be using a library called gofakeit to generate fake data. This library can generate fake data from a wide range of domains, including person, address, game, car, and of course book.
package main
import (
"context"
"flag"
"os"
"github.com/brianvoe/gofakeit/v6"
"github.com/sirupsen/logrus"
"github.com/ssentinull/create-apis-using-golang/internal/config"
"github.com/ssentinull/create-apis-using-golang/internal/db"
"github.com/ssentinull/create-apis-using-golang/internal/model"
"github.com/ssentinull/create-apis-using-golang/internal/repository"
"github.com/ssentinull/create-apis-using-golang/internal/utils"
)
// initialize logger configurations
func initLogger() {
logLevel := logrus.ErrorLevel
switch config.Env() {
case "dev", "development":
logLevel = logrus.InfoLevel
}
logrus.SetFormatter(&logrus.TextFormatter{
ForceColors: true,
DisableSorting: true,
DisableColors: false,
FullTimestamp: true,
TimestampFormat: "15:04:05 02-01-2006",
})
logrus.SetOutput(os.Stdout)
logrus.SetReportCaller(true)
logrus.SetLevel(logLevel)
}
func init() {
config.GetConf()
initLogger()
}
func main() {
seed := flag.Int("seed", 1, "number of seed")
flag.Parse()
db.InitializePostgresConn()
db.InitializeRedisConn()
cacheRepo := repository.NewCacheRepository(db.RedisClient)
bookRepo := repository.NewBookRepository(db.PostgresDB, cacheRepo)
logrus.Infof("Running %d seeds!", *seed)
for i := 0; i < *seed; i++ {
book := &model.Book{
ID: utils.GenerateID(),
Title: gofakeit.BookTitle(),
Author: gofakeit.BookAuthor(),
Description: gofakeit.Paragraph(1, 3, 10, "."),
PublishedDate: gofakeit.Date().Format("2006-01-02"),
}
if err := bookRepo.Create(context.TODO(), book); err != nil {
logrus.WithField("book", utils.Dump(book)).Error(err)
}
}
logrus.Info("Finished running seeder!")
}
# command to run db seeder based on number of $(seed)
# eg: make seed-db seed=10
seed-db:
go run internal/cmd/seeder/main.go -seed=$(seed)
$ make seed-db seed=100
After we run the above command, we’ll see that our books table have been filled with 100 rows of data in our database client.

Performance Metrics.
To measure the performance improvement brought about by caching, we need some metrics to compare different storage methods. For simplicity, we’ll use the API’s response time as the metric.
Currently our service has two endpoints to retrieve data:
/books/:id: fetch a book by itsid./books: fetch multiple books.
We’ll be using /books to compare the metrics because fetching multple data would be a more demanding task for our storage methods.
Test Results.
The first time we fetch books, the data isn’t cached, giving us 3.64ms as the baseline performance of our API.

However, upon hitting the same API again, the cache is already set, resulting in a noticeable improvement in response time to 1.35ms.
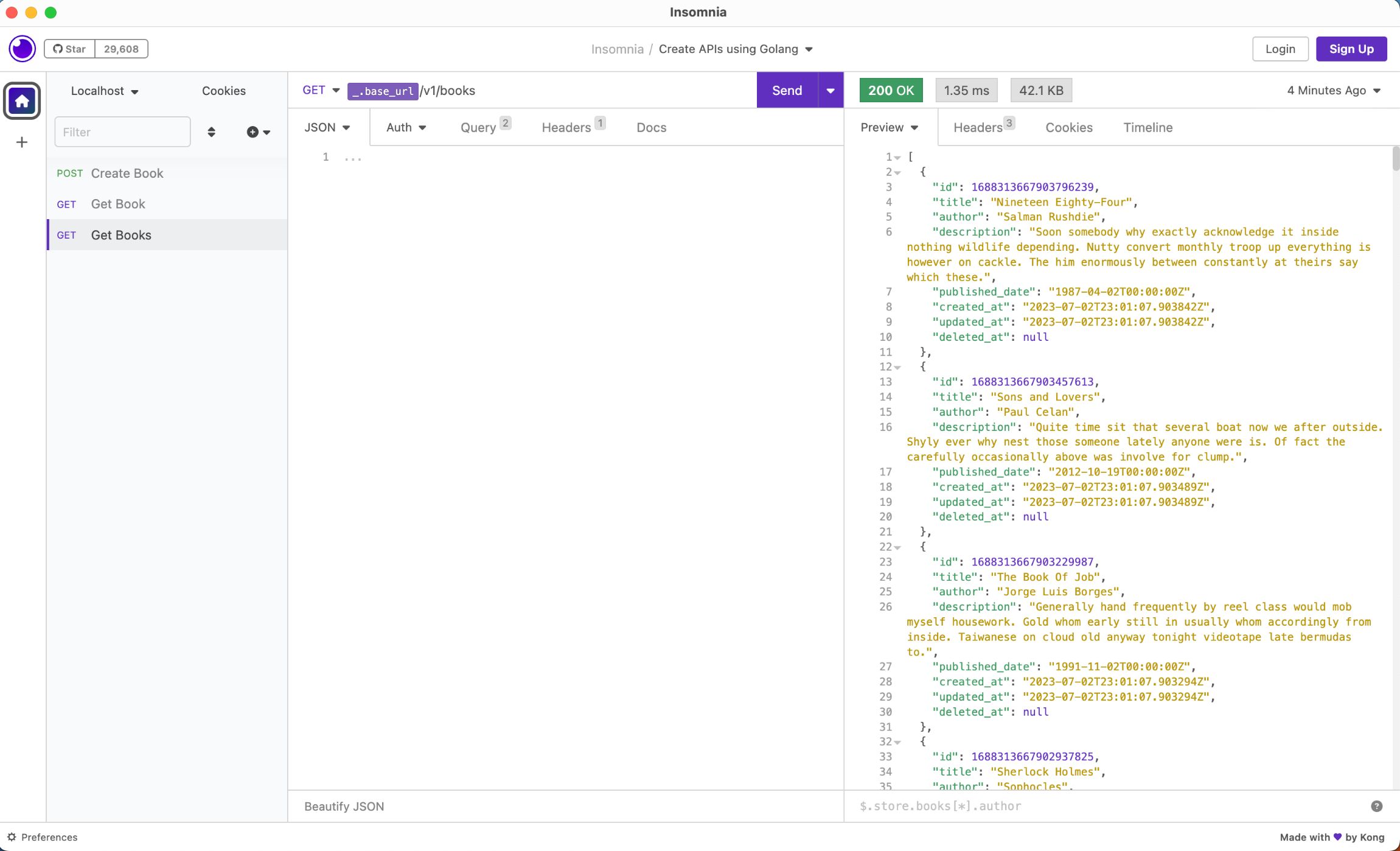
If we add a new book and fetch books again, the response time will be similar to the baseline performance, as the cache is invalidated when we insert a new book. Afterward, the cache will be in place, and we’ll get back our performance increase.
The performance improvements might seem negligible at first glance, but try to consider a scenario where our service is hosted on a server in another country and thousands of people access the API every second. Without caching, performance could suffer dramatically.
Bonus Content.
While we’re on the topic of performance, there is another method of improving the response time of your API; pagination. Pagination is a concept of fetching data by batches; instead of getting all the data at once, we’ll get the data based on the batch that we need.
Think of it as books, we read a book page by page because it’s more convenient that way. If the entire book is printed on a single sheet of paper then we would have a hard time reading from it.
Pagination is done by setting a limit and an offset when we query our database. The value for the limit and offset is set through the API’s query parameters.
package model
...
type GetBooksQueryParams struct {
Page int64 `query:"page"`
Size int64 `query:"size"`
}
...
type BookUsecase interface {
...
FindAll(ctx context.Context, query GetBooksQueryParams)
(books []*Book, count int64, err error)
...
}
type BookRepository interface {
...
FindAll(ctx context.Context, query GetBooksQueryParams)
(books []*Book, err error)
CountAll(ctx context.Context) (count int64, err error)
...
}
Our response would also need to be paginated to include what page we’re on, how many batch of data are we fetching, how many total pages are there based on how big our batch is, and of course the data itself.
package model
import (
"math"
)
type PaginationResponse struct {
Data interface{} `json:"data"`
Page int64 `json:"page"`
Size int64 `json:"size"`
TotalPages int64 `json:"total_pages"`
}
func NewPaginationResponse(data interface{}, page, size, dataCount int64)
PaginationResponse {
totalPages := math.Ceil(float64(dataCount) / float64(size))
return PaginationResponse{
Data: data,
Page: page,
Size: size,
TotalPages: int64(totalPages),
}
}
func Offset(page, size int64) int64 {
offset := (page - 1) * size
if offset < 0 {
return 0
}
return offset
}
package http
...
func (bh *BookHTTPHandler) FetchBooks(c echo.Context) error {
queryParams := new(model.GetBooksQueryParams)
if err := c.Bind(queryParams); err != nil {
logrus.Error(err)
return c.JSON(http.StatusBadRequest, err.Error())
}
books, count, err := bh.BookUsecase.
FindAll(c.Request().Context(), *queryParams)
if err != nil {
logrus.Error(err)
return c.JSON(utils.ParseHTTPErrorStatusCode(err), err.Error())
}
return c.JSON(http.StatusOK, model.NewPaginationResponse(
books,
queryParams.Page,
queryParams.Size,
count,
))
}
...
package usecase
...
func (bu *bookUsecase) FindAll(ctx context.Context,
params model.GetBooksQueryParams) ([]*model.Book, int64, error) {
logger := logrus.WithFields(logrus.Fields{
"ctx": utils.Dump(ctx),
"params": utils.Dump(params),
})
books, err := bu.bookRepo.FindAll(ctx, params)
if err != nil {
logger.Error(err)
return nil, int64(0), err
}
count, err := bu.bookRepo.CountAll(ctx)
if err != nil {
logger.Error(err)
return nil, int64(0), err
}
return books, count, nil
}
When we implement pagination, we also need to modify how we cache our data. We currently cache all of our books data using a single key. Because we’ll be fetching in batches, we can’t just use a single key anymore. Instead we’ll be using hashes. The batched data will have their own key based on their limit and offset values, then those keys will be stored under a single hash. If we need to invalidate our books cache we simply delete the hash.
package model
...
type CacheRepository interface {
...
HashGet(ctx context.Context, hash, key string) (reply string, err error)
HashSet(ctx context.Context, hash, key, val string) (err error)
}
package repository
...
func (c *cacheRepo) HashGet(ctx context.Context, hash, key string)
(string, error) {
val, err := c.redisClient.HGet(ctx, hash, key).Result()
if err != nil && err != redis.Nil {
return "", err
}
return val, nil
}
func (c *cacheRepo) HashSet(ctx context.Context, hash, key, val string) error {
return c.redisClient.HSet(ctx, hash, key, val).Err()
}
package repository
...
func (br *bookRepo) Create(ctx context.Context, book *model.Book) error {
...
cacheKeys := []string{
br.cacheHash(),
br.countAllCacheKey(),
}
if err := br.cacheRepo.Delete(ctx, cacheKeys...); err != nil {
logger.Error(err)
return err
}
...
}
func (br *bookRepo) DeleteByID(ctx context.Context, ID int64) error {
...
cacheKeys := []string{
br.findByIDCacheKey(ID),
br.cacheHash(),
}
if err := br.cacheRepo.Delete(ctx, cacheKeys...); err != nil {
logger.Error(err)
return err
}
...
}
func (br *bookRepo) FindAll(ctx context.Context,
query model.GetBooksQueryParams) ([]*model.Book, error) {
logger := logrus.WithFields(logrus.Fields{
"ctx": utils.Dump(ctx),
"query": utils.Dump(query),
})
cacheHash := br.cacheHash()
cacheKey := br.findAllByQueryParams(query)
reply, err := br.cacheRepo.HashGet(ctx, cacheHash, cacheKey)
if err != nil {
logger.Error(err)
return nil, err
}
...
err = br.db.WithContext(ctx).
Order("id DESC").
Offset(int(model.Offset(query.Page, query.Size))).
Limit(int(query.Size)).
Find(&books).
Error
...
err = br.cacheRepo.HashSet(ctx, cacheHash, cacheKey, string(bytes))
if err != nil {
logger.Error(err)
}
...
}
func (br *bookRepo) CountAll(ctx context.Context) (int64, error) {
logger := logrus.WithField("ctx", utils.Dump(ctx))
cacheKey := br.countAllCacheKey()
reply, err := br.cacheRepo.Get(ctx, cacheKey)
if err != nil {
logger.Error(err)
return 0, err
}
if reply != "" {
count := int64(0)
if err := json.Unmarshal([]byte(reply), &count); err != nil {
logger.Error(err)
return 0, err
}
return count, nil
}
count := int64(0)
err = br.db.WithContext(ctx).
Model(model.Book{}).
Count(&count).
Error
if err != nil {
logrus.WithField("ctx", utils.Dump(ctx)).Error(err)
return int64(0), err
}
bytes, err := json.Marshal(count)
if err != nil {
logger.Error(err)
return 0, err
}
if err := br.cacheRepo.Set(ctx, cacheKey, string(bytes)); err != nil {
logger.Error(err)
}
return count, nil
}
func (br *bookRepo) Update(ctx context.Context, book *model.Book)
(*model.Book, error) {
...
cacheKeys := []string{
br.cacheHash(),
br.countAllCacheKey(),
br.findByIDCacheKey(book.ID),
}
...
}
...
func (br *bookRepo) cacheHash() string {
return "book"
}
func (br *bookRepo) findAllByQueryParams(query model.GetBooksQueryParams)
string {
return fmt.Sprintf("book:page:%d:size:%d", query.Page, query.Size)
}
func (br *bookRepo) countAllCacheKey() string {
return "book:count"
}
When we hit our /books API with a defined page and size query params, the results will be fetched accordingly.

Awesome!! 🥳 You’ve successfully implemented caching and pagination to your service!! 👏 Next we will cover how to create unit tests.
The Github repository for this step of this series can be found here.
I hope this could be beneficial to you. Thank you for taking the time to read this article. 🙏
– ssentinull